特点
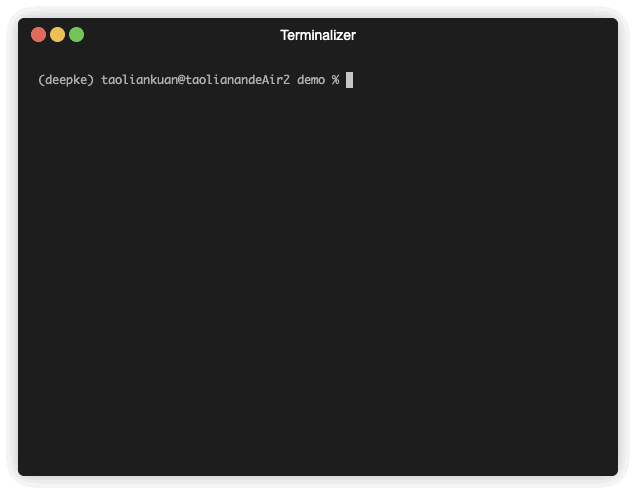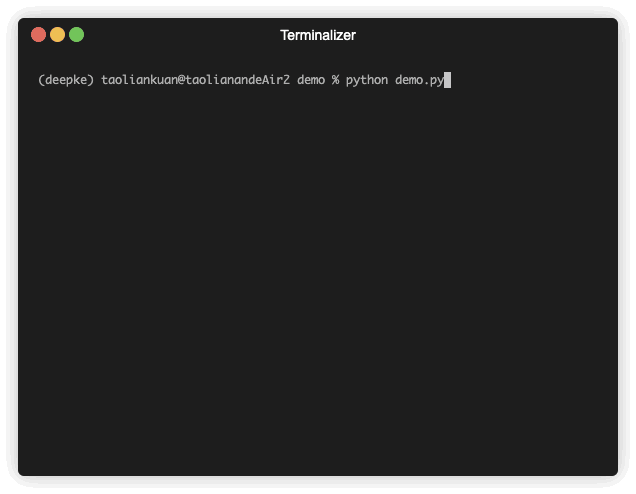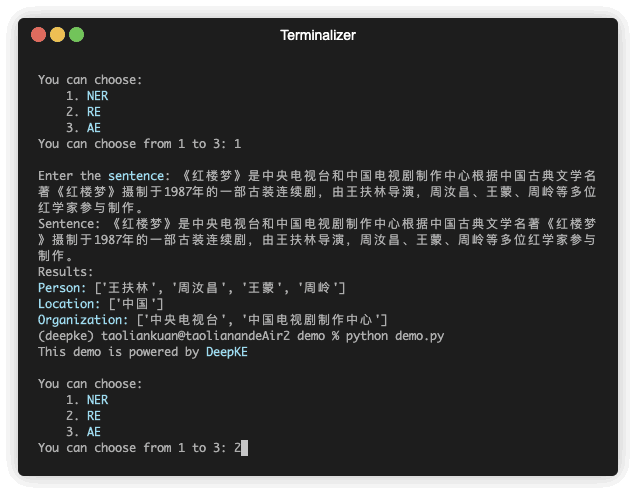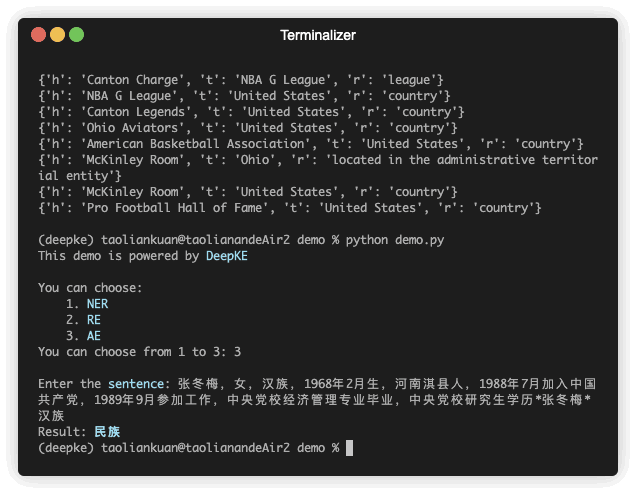
DeepKE 是一个支持低资源、长篇章、多模态的知识抽取工具,学术界和工业界的用户可以定制输入的数据集和模型实现命名实体识别、关系抽取和属性抽取功能。
开源开放的知识图谱抽取工具
DeepKE是一个开源和可扩展的知识图谱抽取工具,支持常规全监督、低资源少样本、长篇章文档和多模态场景,覆盖各种信息抽取任务包括命名实体识别、关系抽取和属性抽取。通过一个统一的框架,DeepKE 允许开发人员和研究人员自定义数据集和模型,并根据他们的需求从非结构化文本中抽取信息。DeepKE针对不同的功能和场景提供了各种功能模块和模型实现,以保持足够的模块化和可扩展性。此外,DeepKE还为初学者提供了全面的文档和 Google Colab 教程。用户可以通过“pip install deepke”安装 DeepKE。我们将长期提供维护以满足新的请求,支持新任务,和修复Bug。
简洁使用
DeepKE 提供各种功能模块,并通过一致的框架组织所有组件。针对中文领域,DeepKE提供开箱即用的支持cnSchema的预训练抽取模型。
模块化和可扩展
训练验证代码和模型架构代码分离,可自定义新模型新数据
支持自动调参
支持通用一行代码自动调参,方便模型调优
Issues
Stars
Forks
开箱即用的知识抽取模型
广泛领域
支持cnSchema体系
贡献者

张宁豫、陶联宽、徐欣、余海洋、叶宏彬、乔硕斐、谢辛、李欣荣、陈想、黎洲波、李磊、梁孝转、姚云志、邓淑敏、王鹏、张文、郑国轴、陈华钧

王昊奋

陈强、熊飞宇

张珍茹、谭传奇、黄非




